
Projects
Instruction Vagueness Analysis for Vision Language Navigation Models
Supervisors: Prof. Bryan Plummer
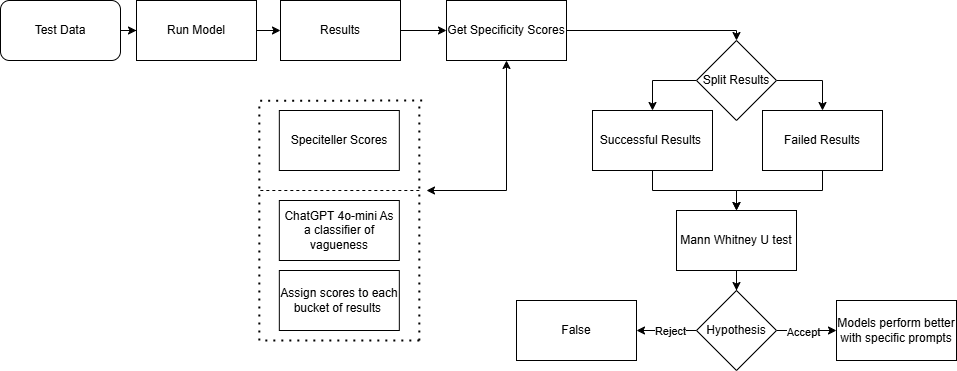
Fig. Workflow
Ever told a robot “just go forward” and hoped for the best? Yeah, it doesn’t go well. In Vision-and-Language Navigation (VLN), vague human instructions tank model performance. To fix that, I built a dual framework: Speciteller scores how specific an instruction is, while GPT-4o-mini checks vagueness in context using the environment.
We ran this across ALFRED and CHORES datasets on SPOC, MOCA, and Episodic Transformers. The takeaway? Specific instructions = higher success. End-to-end models with memory (like Episodic Transformers) handle ambiguity best, while others need clear directions.
Key Contributions:
- Dual Vagueness Framework: Combined Speciteller regression with GPT-4o-mini classification to capture both lexical and contextual vagueness in navigation instructions.
- Large-Scale Analysis: Evaluated vagueness impact across ALFRED and CHORES datasets on SPOC, MOCA, and Episodic Transformers.
- Architectural Insights: Showed that intermediate fusion + memory architectures are more robust against vague instructions, while late-fusion models struggle.
- Practical Strategies: Proposed vagueness-aware losses, data augmentation with paraphrasing, and adaptive attention controllers to make agents smarter at handling ambiguous commands.
Carbon Credit Calculation using Event Extraction from Unstructured Data
Bachelor's ThesisSupervisors: Prof. Surekha Bhanot, Dr. Riza Batista-Navarro
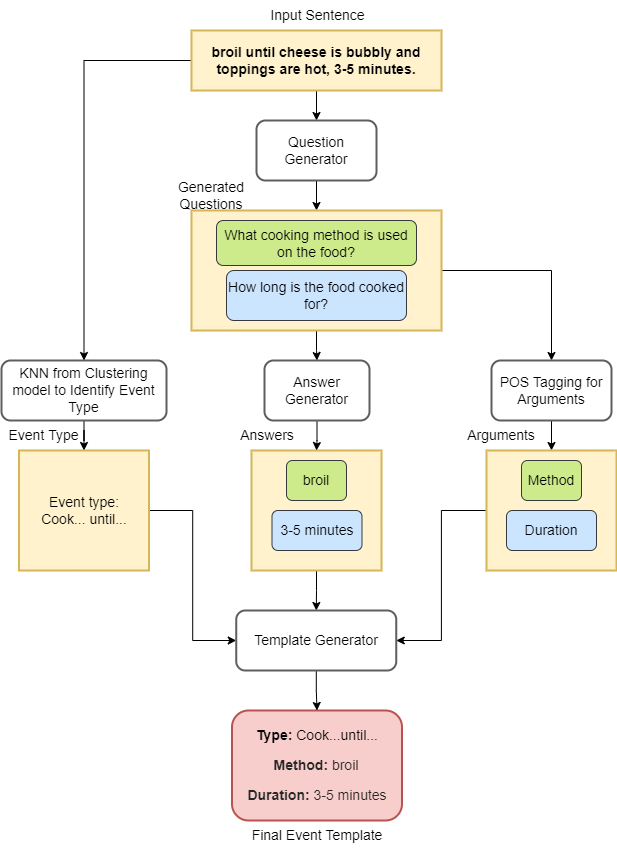
Fig. Event Extraction Example

Fig. Model Architecture
Have you ever wondered how many carbon credits you're consuming just by cooking a recipe you found online? Given the huge wave of sustainability washing over the UK, it was a given to do my thesis to help identify the amount of carbon emissions one causes when doing mundane tasks in their day-to day. An important factor in identifying the emissions is actually identifying the events that would result in these. For recipes, I chose to focus on the cooking methods (such as sauteeing, baking, boiling, etc.). Given that recipes are generally in pretty unstructured formats across the internet, my research focused around event extraction from unstructured data.
To do this, I used a combination of human-in-the-loop learning and HDBScan clustering to identify common events in recipes, then used a combination of fine-tuned transformers (Siamese BERT, T5) to generate relevant questions the model could ask itself to correctly identify event details such as what cooking event, how long for, at what temperature, etc. This was then integrated into API's for a chrome extension that could estimate the carbon credits consumed during cooking.
Key Contributions:
- Innovative Carbon Emission Model: Applied interactive machine learning and machine reading comprehension to create a model that calculates carbon emissions in recipes based on the extracted event templates
- Semi-Supervised Event Extraction: Designed a system that uses HDBScan clustering and human-in-the-loop training to extract events from unstructured data without pre-existing annotations.
- Transformer-Based Question Generation: Fine-tuned BERT and T5 models to generate relevant questions and refine event details. Incorporated POS tagging to improve accuracy in event detection.
- Research Excellence: Demonstrated strong problem-solving, critical thinking, and communication skills through collaborative work with academic mentors and experts. Enhanced teamwork and model design abilities throughout the project.
C-Former: A Novel Vision Transformer-Based Architecture for EEG Emotion Classification
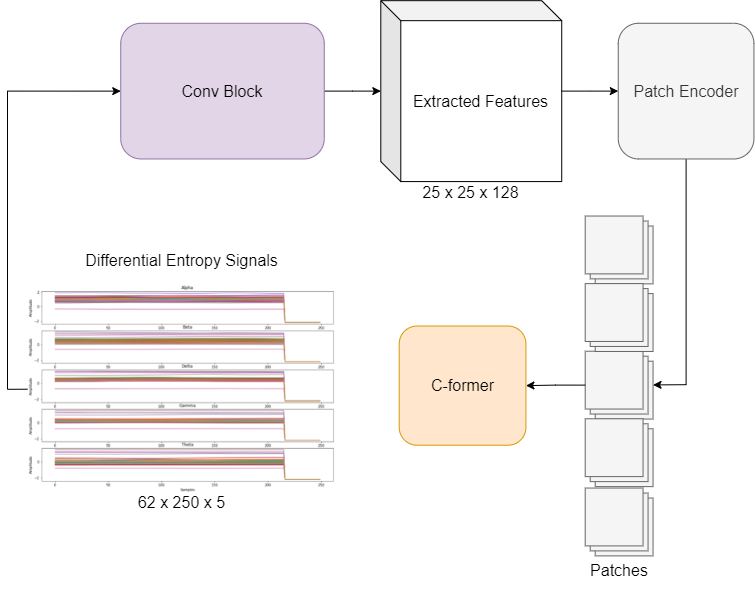
Fig. Model Approach
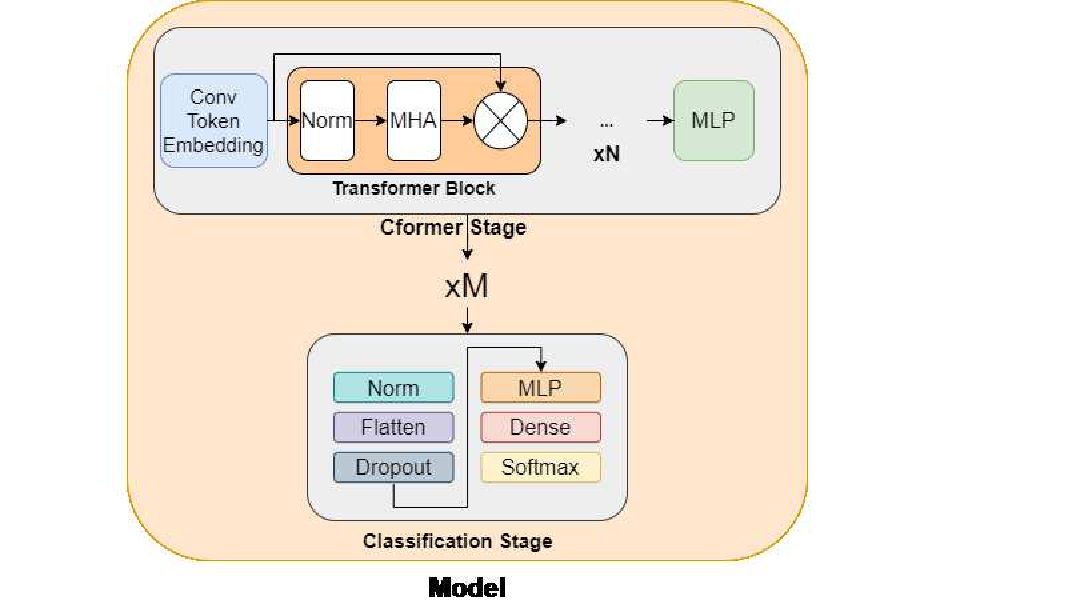
Fig. CFormer Block Architecture
This research introduced C-Former, a cutting-edge transformer-based architecture designed for emotion classification using EEG signals. Electroencephalography (EEG) is a non-invasive method of measuring the brain's electrical activity in response to stimuli and has numerous applications in clinical and research settings. The proposed model incorporates convolutional token embedding layers and a convolutional feature extractor to enhance the representation of spatial and temporal features in EEG data.
The aim was to develop a robust and efficient method for emotion recognition using EEG signals. By leveraging the power of transformers, C-Former addresses challenges such as variations in data and the need for precise feature extraction, outperforming traditional models while maintaining competitive performance with state-of-the-art approaches.
Key Contributions:
- Transformer-Based Innovation: C-Former combines convolutional layers for token embedding with transformer modules to capture both local and global features in EEG data.
- Benchmark Performance: Experimental results on the SEED dataset demonstrate that C-Former achieves superior accuracy compared to previous models, while being more robust to variations in input data.
- First-of-Its-Kind Application: To the best of our knowledge, this is the first work that employs transformers specifically for EEG-based emotion recognition.